
Wikipedie:Žádost o komentář/Základní písmena v šabloně Latinka
Tato stránka obsahuje archiv žádosti o komentář; už ji laskavě needitujte.
Žádost o komentář skončila výsledkem:
ŽOK komunitu prakticky nezaujal, diskuse se účastnili především uživatelé Palu a Standazx, kteří nedospěli ke shodě ani řešení. V této situaci se proto jako nejvhodnější řešení jeví Okinův návrh, podle kterého je třeba nalézt akademický zdroj/zdroje definující latinku a šablonu mu/jim přizpůsobit (případně změnit charakter šablony ze "základní" na "klasickou" latinku). --Podzemnik 7. 10. 2010, 19:33 (UTC)
Základní písmena v šabloně Latinka
[editovat | editovat zdroj]O co jde: Spor o to, která písmena by měla být uvedena jako základní písmena v šabloně Latinka.
Vytvořil jsem šablonu Šablona:Latinka, ve které je sekce Základní písmena. Objevil se spor mezi mnou (Wikipedista:Standazx) a Wikipedista:Palu o to, která písmena považovat za základní. Podle mého názoru do této kategorie patří všechna v současné době používaná (nearchaická) písmena bez diakritického znaménka, čili písmena anglické abecedy a další písmena, jako jsou Þ, ß nebo Ə a případná další, která neobsahují diakritické znaménko. Wikipedista:Palu má názor takový, že za základní písmena by měla být považována pouze písmena anglické abecedy, zatímco písmena Þ, ß nebo Ə by za základní považována být neměla, neboť se nepoužívají v dostatečném počtu jazyků (ovšem nedodal jasné kritérium, podle kterého by bylo možné tento dostatečný počet určit - všechny nebo výrazná většina není podle mého dostatečně jasné a konkrétní kritérium). Více v Diskuse k šabloně:Latinka.
Pokus o domluvu
[editovat | editovat zdroj]Pokusy dospět k závěru na stránce Diskuse k šabloně:Latinka selhávají, jelikož se diskuse účastníme pouze dva. Z tohoto důvodu chci požádat o komentář k tomuto problému i ostatní Wikipedisty.
Analýza situace ohledně podobné šablony na jiných wikipediích
[editovat | editovat zdroj]Na wikipediích v jiných jazycích existují různé přístupy k podobné šabloně:
- pouze písmena anglické abecedy:
- německá verze de:Vorlage:Navigationsleiste Lateinisches Alphabet - šablona o těchto písmenech ale mluví jako o základních písmenech abecedy, nikoliv o základních písmenech latinky
- malajská verze ms:Abjad Latin
- portugalská verze pt:Predefinição:Alfabeto Latino - o písmenech mluví jako o základních písmenech abecedy podle ISO, k thornu není tato šablona přiřazena
- čínská verze zh:Template:Latin alphabet - o písmenech mluví jako o základních písmenech abecedy podle ISO, k thornu je tato šablona přiřazena
- písmena abecedy daného jazyka
- estonská verze et:Mall:Tähestik
- islandská verze is:Snið:Stafrófið
- anglická abecedna + písmena s diakritikou používaná v daném jazyce:
- krymskotatarská verze crh:Şablon:Latin elifbesi
- anglická abeceda + některá písmena s diakritickým znaménkem
- slovinská verze sl:Predloga:Latinska abeceda
- švédská verze sv:Mall:Latinska alfabetet - (anglickou abecedu označuje jako základní písmena, ostré S jako ligaturu, thorn a obrácené E neobsahuje vůbec - není možné posoudit do jaké kategorie zařadit Thorn) - šablona k thornu není přirazena
- anglická abeceda + některá přidaná písmena včetně ostrého S a thornu:
- dolnoněmecká verze als:Vorlage:Lateinisches Alphabet (bez kategorizace)
- korejská verze ko:틀:로마자
- latinská verze la:Formula:Abecedarium Latinum
- nizozemská verze nl:Sjabloon:Navigatie Latijns alfabet
- ruská verze ru:Шаблон:Латинский алфавит
- písmena abecedy daného jazyka + některá další přidaná písmena včetna ostrého S a thornu
- dánská verze da:Skabelon:Latinske bogstaver
- anglická abeceda + některá přidaná písmena včetně ostrého S a thornu + digrafy, trigrafy ...
- bretoňská verze br:Patrom:Lizherenneg latin
- korsická verze co:Template:Modellu alfabetu latinu
- italská verze it:Template:Alfabeto latino
- Snaha o kompletní seznam písmen
- dolnosrbská verze dsb:Pśedłoga:Łatyński alfabet
- perská verze fa:الگو:حروف لاتین یونیکد
- francouzská verze fr:Modèle:Table de l'alphabet latin
- hornosrbská verze hsb:Předłoha:Łaćonski alfabet
- verze v indonéštině id:Templat:Huruf Latin
- norská verze no:Mal:Latinsk alfabet
- polská verze pl:Szablon:Alfabet łaciński
- slovenská verze sk:Šablóna:Latinka
- thajská verze th:แม่แบบ:อักษรละตินทั้งหมด
Anglická verze šablony en:Template:Latin alphabet písmena thorn a ostré S vůbec neobsahuje, na druhou stranu šablona je k těmto písmenům přiřazena, takže je obtížné rozhodnout, kam tato písmena patří.
Výše uvedené šablony jsou ovšem definovány jako šablony pro abecedu (alphabet, alfabet, alfabeto, ...), tudíž i dělení písmen je vedeno z hlediska abecedy, nikoli z hlediska písma jako celku.
V šablonách není shoda ani v názvech skupin písmen, např. polská šablona označuje všechna písmena, včetně thornu a ostrého S, jako latinská písmena, slovenská šablona mluví o latinské abecedě, písmenech s diakritickým znaménkem a jiných písmenech.
Zdroje, které definují latinku
[editovat | editovat zdroj]Základní abeceda:
- Latinská, řecká a Morseho abeceda
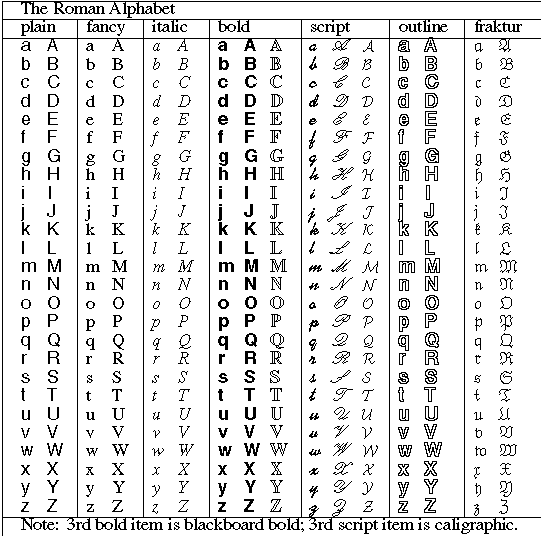
- The Roman alphabet
- Tabulka znaků - Základní latinka
- Quadrata rustika
{kind=link}
{kind=link}
{kind=link}
Archaická a klasická abeceda:
{kind=link}
Z uvedeného vyplývá, že to, co prosazuje Standazx, se nazývá klasická latinská abeceda, zatímco druhá se nazývá buď Římská nebo základní latinská abeceda. To nám jednak pomůže si ujednotit terminologii a jednak nám to ukáže, co to vlastně ta základní latinka je. Palu 9. 5. 2010, 20:50 (UTC)
- Latinská, řecká a Morseho abeceda- slovenská stránka, ve slovenštině může být jiná terminologie (např. slovenské slovo cesta může být do češtiny přeloženo jako cesta nebo jako silnice),
- Co chcete přeložit na Latinská, řecká a Morseho abeceda? :-) Palu 24. 5. 2010, 07:03 (UTC)
- Např. v angličtině se pojem Latin alphabet běžně používá jak pro abecedu jazyka latina tak pro písmo latinku. V češtině se tyto dva pojmy oddělují, latinská abeceda je název pro soubor písmen, latinka je název pro písmo. Jak k tomuto přistupují na Slovensku, nevím.--Standazx 29. 5. 2010, 05:46 (UTC)
- Co chcete přeložit na Latinská, řecká a Morseho abeceda? :-) Palu 24. 5. 2010, 07:03 (UTC)
- The Roman alphabet - Podle tohoto dokumentu jsou tedy písmena A B C D E F G H I J K L M N O P Q R S T U V W X Y Z písmeny římské abecedy (ale stejně tak se jedná o písmena anglické abecedy),
- V čem by nás měla zajímat shoda římské a anglické abecedy? Anglickou abecedu bych do tématu vůbec netahal, nijak nám to se základní latinkou nepomůže. Palu 24. 5. 2010, 07:03 (UTC)
- Proč by nepomohla? Pokud pro soubor písmen A B C D E F G H I J K L M N O P Q R S T U V W X Y Z existuje jednoznačný název, nevidím důvod, proč ho nepoužít v šabloně, narozdíl od názvu, který je sporný.
- V čem by nás měla zajímat shoda římské a anglické abecedy? Anglickou abecedu bych do tématu vůbec netahal, nijak nám to se základní latinkou nepomůže. Palu 24. 5. 2010, 07:03 (UTC)
- Tabulka znaků - Základní latinka - v odkazovaném dokumentu není uveden žádný název, ani písma, ani abecedy. Podle znaků obsažených v dokumentu se jedná o výběr znaků ze znaků kódovaných v ASCII,
- název je tam uveden ten co jsem napsal Palu 24. 5. 2010, 07:03 (UTC)
- Na to se dá říct pouze jediné: Tabulka znaků - nekompletní seznam písmen latinky --Standazx 29. 5. 2010, 05:46 (UTC)
- název je tam uveden ten co jsem napsal Palu 24. 5. 2010, 07:03 (UTC)
- Quadrata rustika - v odkazovaném dokumentu jsou uvedeny pouze názvy fontů, nikoliv název písma nebo abecedy,
- Původní — klasická — latinská abeceda - dokazuje, že pojem klasická písmena znamená anglickou abecedu bez písmen J, U, W, Y, Z
{kind=link}
Kromě zdroje prvního nelze zdroje považovat za zdroje oficiální. --Standazx 23. 5. 2010, 05:43 (UTC)
- Zkuste sehnat lepší. Palu 24. 5. 2010, 07:03 (UTC)
Návrhy řešení
[editovat | editovat zdroj]Okino
[editovat | editovat zdroj]Zdá se mi, že Vaše diskuse směřuje k vlastnímu výzkumu. Nalezněte věrohodný, nejlépe akademický zdroj, který by definoval, co jsou to základní písmena latinky, a šablonu upravte podle toho. Pokud bude zdrojů víc a budou se lišit, můžete se pak už celkem arbitrárně dohodnout, zda do základních písmen uvedete všechna, která jsou aspoň jednou zařazena mezi základní, nebo naopak jen ta, která jsou mezi základní zařazena pokaždé. Pokud nebudete se zdroji úspěšní, pak se mi jeví jako vhodná varianta změnit označení "základní" na "klasické" a vycházet z latinské latinky, o jejímž souboru - podle ostatních Wikipedií - panuje určitá obecná shoda. Okino 7. 5. 2010, 22:42 (UTC)
Palu
[editovat | editovat zdroj]Písmena Þ, ß nebo Ə nelze považovat za základní písmena. Nepovažují je za ně ani ostatní jazykové mutace wiki. Problém je v tom, že když je něco základní, užívá to nějaká většina. Tato písmena užívá jen pár jazyků a v případě Ə jen turkická skupina. Pokud se přejmenuje kategorie na klasická písmena, jak navrhuje Okino, také nebudu mít žádný problém. Ale takto jsou míchána jablka s hruškami. Palu 8. 5. 2010, 10:29 (UTC)
- Ještě chci dodat, že svůj názor určitě neformuluji tak, že by byla základními písmeny písmena anglické abecedy. Palu 8. 5. 2010, 10:30 (UTC)
Standazx
[editovat | editovat zdroj]Písmena Þ, ß a Ə mají společnou vlastnost s písmeny anglické abecedy to, že se jedná o písmena bez diakritiky, a dále to, že jsou v současné době aktivně používané v jazycích, které nejsou současně zapisovány i jiným písmem. Z tohoto hlediska jsou rovnocenná s písmeny anglické abecedy (a z tohoto hlediska se tedy nejedná o míchání hrušek s jablky). Ostatní jazykové mutace nepovažují tato písmena za základní vzhledem k pojmu abeceda, šablona na české wikipedii je ale definována jako šablona pro písmo, které se nazývá latinka. Pojem klasická písmena může narazit na souvislost s abecedou klasické latiny, která obsahuje pouze písmena A, B, C, D, E, F, G, H, I, K, L, M, N, O, P, Q, R, S, T, V, X, Y, Z, písmena J, U, W v ní obsažena nejsou.
Navržené možnosti řešení:
- Množinu písmen A, B, C, D, E, F, G, H, I, J, K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z označit názvem Písmena anglické abecedy nebo písmena abecedy podle ISO/IEC 646, případně písmena latinky obsažená v ISO/IEC 646, které je vzhledem k těmto písmenům správné.
- Uvést do šablony písmena A, B, C, D, E, F, G, H, I, J, K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z, Ə, ß, Þ a označit je jako nearchaická písmena bez diakritiky, což je korektní název pro tuto skupinu písmen.
- Šablonu přepracovat na šablonu vycházející z české abecedy, to, která písmena jsou součástí české abecedy je jednoznačně dáno.
- Šablonu přepracovat na šablonu, která nebude pro latinku, ale pro abecedu.
--Standazx 9. 5. 2010, 10:02 (UTC)
- To je absurdní. Je mi jedno, jestli se kategorie bude jmenovat "klasická písmena" nebo "základní písmena", ale rozhodně nesmí obsahovat písmena, která neužívá skoro žádný jazyk. Ta patří do jiné kategorie vzhledem k názvu. Název "anglická abeceda" by potom byl anglocentrický, což je taktéž nepřípustné. Stejně jako by bylo nevhodné přepracovávat to na čechocentrickou formu. Tudíž nemohu s těmito návrhy souhlasit. V šabloně musí být uvedena kategorie, která bude obsahovat pouze a jen základní sadu písmen, ať už chcete užívat terminologii jakoukoliv. Palu 9. 5. 2010, 17:19 (UTC)
- Toto je pouze komentář odpovědi wikipedisty Palu, nikoliv návrh řešení: Pokud vezmeme jednotlivá písmena latinky a stanovíme jako kritérium toho, zda se písmeno používá v daném jazyce či nikoliv, to zda je obsaženo v abecedě daného jazyka, zjistíme, že různá písmena písmena jsou využívána v různém počtu jazyků. Některá nejsou používána v žádném jazyku, některá ve všech jazycích používajících latinku, jiná třeba v 90% jazyků, jiná v 70% jazyků, jiná v 10% jazyků. Jak navrhuje Okino, mohou být jako základní písmena zvolena písmena, která se vyskytují alespoň v jednom zdroji nebo naopak která se vyskytují pouze ve všech zdrojích. Vzhledem k tomu, že jsem zatím nenašel oficiální definici pojmu základní písmena latinky, můžeme prozatímně za zdroj o oficiálních písmenech považovat výskyt písmen v abecedách jednotlivých jazyků. Tedy za základní písmena můžeme považovat buď písmena vyskytující se alespoň v jedné abecedě a nebo pouze písmena, která se vyskytují ve všech abecedách. V prvním případě tedy písmena anglické abecedy + Þ, ß, Ə, v druhém případě pouze písmena A, B, D, E, F, G, H, I, L, M, N, O, P, R, S, T, U - písmena K, Q, W, Y nejsou součástí rumunské abecedy, písmeno V není součástí polské abecedy, písmena J a Z nejsou součástí vietnamské abecedy, písmeno X není součástí lotyšské a litevské abecedy, písmeno C není součástí islandské, faerské, uzbecké a estonské abecedy (estonská abeceda neobsahuje písmena C, Q, W, X a Y), turecká abeceda neobsahuje písmena Q, W, X, chorvatská, slovinská a srbská abeceda neobsahují písmena Q, W, X, Y. A to jsem zatím neprošel zdaleka všechny abecedy. --Standazx 9. 5. 2010, 18:46 (UTC)
- Nemáte pravdu, V je omezeně součástí polské abecedy: "Litery z alfabetu łacińskiego: Q, V i X nie są zaliczane do liter polskiego alfabetu, gdyż w polskim słowotwórstwie nie ma potrzeby ich stosowania. Występują one tylko w wyrazach pochodzenia obcego, czyli zapożyczonych." Překlad: "Písmena z latinky Q, V a X nejsou zahrnuta do písmen polské abecedy, poněvadž v polské slovotvorbě jich není potřeba. Vyskytují se jen ve výrazech cizího původu, čili v zápůjčkách." U dalších abeced je tomu tak podobně.
- V tomhle se prostě shodnout nemůžeme. Exotická písmena za základní považovat nelze a naopak písmena C, J, K, Q, V, W, Z základní evidentně jsou, jelikož je využívá většina jazyků. Mě ta debata opravdu přijde absurdní. V tomhle základu se evidentně nemůžeme shodnout. Mě se líbí Okinovo řešení - přejmenovat na "klasická písmena" a zařadit klasickou latinskou latinku v její moderní verzi, které vy říkáte anglická. Což je vlastně pouze změna termínu na údajně vhodnější, přičemž ale o zjevnosti výkladu slova "základní" já nepochybuji. Když je to ale nutné k vyřešení, jsem pro. Palu 9. 5. 2010, 19:58 (UTC)
- Věta, že V je omezeně součástí polské abecedy, je docela zajímavý výraz, zvláště, když hned v následující polské větě je uvedeno, že se nepočítá do písmen polské abecedy (dvě poněkud rozporná tvrzení, nemyslíte?). Každopádně je zvláštní, že Þ protože se vyskytuje málo, považujete za exotické písmeno latinky, ale V i přesto, že se v polštině vyskytuje málo, ho vzhledem k polštině za exotické nepovažujete. Přitom V je v polštině ve stejné situaci jako Þ v celé latince. Jinak jako příklad si dovolím uvést srbštinu, která písmena Q, W a X nepoužívá vůbec, slova do srbštiny se přepisují foneticky (např. software -> softver), na stránce sr:Isak Njutn jsou i další příklady jak se do Srbštiny přepisují jména (např. Lagranž). V srbštině se ani tato písmena vyskytovat nemohou, neboť nemají ekvivalenty v cyrilici. Podle srbského zákona jsou latinka a cyrilice v Srbsku rovnocenné.
Krátká úvaha. Vezměme například písmeno a. Z něho vznikla nebo mohou vzniknout například písmena å, ã, ǎ, â, à, á, ȧ. Základem pro tato odvozená písmena je písmeno a, takže o něm lze prohlásit, že pro tato písmena je písmenem základním. Vezměme například písmena č, ć, c̃, ĉ. Pro ně je základním písmenem písmeno c. Pak můžeme vzít písmena š, ś, s̉, s͌, s̃, pro která je základním písmenem písmeno s. Pak třeba můžeme vzít písmena Þ̀, Þ̈, Þ̢, pro která je základním písmenem písmeno Þ.
Ohledně pojmu základní písmena jsem podal dotaz na ÚJČ, kteří mi odpověděli, že mi nemohou kvalifikovaně odpovědět, neboť nemají dostatek podkladů. Pouze ocitovali odstavec normy, která definuje základní mezinárodní abecedu jako množinu základních písmen bez diakritiky a modifikovaných tahů a dále mě odkázali na ÚNMZ, kam jsem položil stejný dotaz, ale zatím jsem neobdržel odpověď. --Standazx 15. 5. 2010, 13:22 (UTC)- V je v polštině exotické písmeno, ale v polských textech existuje (např. jméno Violetta Kubasińska). To ale neznamená, že budeme Þ řadit mezi základní písmena latinky. Ostatně tak se vyjádřil i ÚJČ. Pro zařazení Þ do základních písmen není žádné opodstatnění. Palu 16. 5. 2010, 17:46 (UTC)
- Jména a příjmení nejsou zrovna nejlepším důkazem pro výskyt znaků v daném jazyce. V českých textech se také vyskytují jména jako Josef Müller, nebo Jan Flüs, a přesto z nich nikdo nevyvozuje, že ü je součástí češtiny. ÚJČ se vyjádřil pouze tak, že základní mezinárodní abeceda se skládá z písmen bez diakritiky a pozměněných tahů. Bližší specifikace, např. to, že by z množiny písmen bez diakritikou měla být vyřazena písmena Þ či Ə, v odpovědi nevidím. Odpověď od ÚNMZ je v podobném smyslu: V normě se slovo základní používá pro písmena bez diakritiky. --Standazx 23. 5. 2010, 05:43 (UTC)
- Co tím chce ÚJČ říci je podle mě evidentní. Kdyby do toho počítal i písmena, která se používají v 1 jazyku světa a která nikdo nezná, výslovně by je vyčetl. Dále si nemyslím, že byste se měl tázat regulátora češtiny na základní latinku, spíše se podívejme na definici slova "základní" (tvořící východisko něčeho, hlavní, nejdůležitější), která koresponduje s výše uvedenými zdroji, které exotická písmenka do základní latinky neřadí. Palu 24. 5. 2010, 06:50 (UTC)
- Přesně tak, evidentní je, že se ÚJČ vyjádřil tak, že nemůže podat kvalifikovanou odpověď, když pouze ocitoval normu, a proto mě odkázal na ÚNMZ, aby mi o tom sdělili víc. A ÚNMZ se vyjádřil podle mě jednoznačně v tom, že pro písmena platí základní = bez diakritiky. Jinak i podle definice slova základní patří Þ mezi písmena základní, protože je to výchozí písmeno (tvořící východisko něčeho, základní písmeno) pro písmena Ꝥ (šestnáctkový kód v Unicode: A764) Ꝧ (šestnáctkový kód v Unicode: A766) (ꝥ (šestnáctkový kód v Unicode: A765) ꝧ (šestnáctkový kód v Unicode: A767)). Navíc i výraz písmeno bez diakritiky a pozměněných tahů z odpovědi ÚJČ je platný pro Þ. --Standazx 29. 5. 2010, 05:46 (UTC)
- No, právě že výchozí absolutně není, ani nemá ve výchozí abecedě původ. Myslím, že ÚJČ písmeno Þ určitě nemyslel. Palu 29. 5. 2010, 10:06 (UTC)
- Přiznám se, že nerozumím. Které písmeno tedy slouží jako základ pro písmena Ꝥ, Ꝧ, Þ̀, Þ̈, Þ̢, když to podle vás není písmeno Þ ? A znovu opakuji, že ÚJČ nemyslel nic nijak, pouze ocitoval jeden odstavec normy a pro výklad pojmu základní písmena mě odkázal na ÚNMZ, jehož názor je tedy podle mě rozhodující, jelikož ÚNMZ je správcem oné normy. --Standazx 30. 5. 2010, 18:47 (UTC)
- Þ je výchozí pro ta písmena, ale základní = tvořící východisko něčeho, hlavní, nejdůležitější. To tohle písmeno z hlediska latinky jako písma nesplňuje, už jen proto, že jej používá jen jedna nebo dvě modifikace latinky. Vše už bylo tak nějak řečeno a už jsem psal, že mi ta debata přijde absurdní. Zdroje výše uvedené jasně základní latinku definují a my tu podle mě řešíme s prominutím naprostou kravinu. Myslím, že jsme se už vyčerpali a nové argumenty nepřijdou, a tak bych asi počkal, jestli nepřidá někdo další nějaký zajímavý názor nebo třeba shrnutí této diskuse. Taky ještě budu rád, když dodáte vyjádření ÚNMZ až ho budete znát, snad také přispěje k dořešení této záležitosti. Palu 30. 5. 2010, 18:58 (UTC)
- Takže děkuji za vysvětlení významu slova základní. Já se totiž domníval, že slovo základní je odvozeno od slova základ, tudíž pokud něco slouží jako základ (něco, na čem se dále dá stavět), může se k tomu bez problémů přidat přídavné jméno základní (např. v počítačové terminologii základní deska = deska, která je základem počítače). Takže přestože Þ je základem pro písmena Ꝥ, Ꝧ, Þ̀, Þ̈, Þ̢, není možné ho nazývat slovem základní. Na druhou stranu vás obdivuji, že máte jednoznačné argumenty k problematice, ke které se nechce vyjádřit ani ÚJČ z důvodu nedostatku podkladů (nechtěl byste jim to vysvětlit, aby v tom také měli jasno?). Odpověď z ÚNMZ zní (cituji): V normě se slovo základní používá pro písmena bez diakritiky. Každopádně jste mi ještě neodpověděl jednoznačně na otázku, v kolika abecedách se musí dané písmeno vyskytovat, aby podle vás bylo možné ho považovat za písmeno základní. Některé písmena prostě jazyky nepoužívají:
- V není obsaženo v abecedě: irštiny, velštiny, dolnolužické srbštiny, hornolužické srbštiny, kašubštiny, polštiny, turkmenštiny, hauštiny, jorubštiny, ajmarštiny, komančštiny, lakotštiny,
- W není obsaženo v abecedě: albánštiny, litevštiny, lotyštiny, faerštiny, islandštiny, irštiny, galicijštiny, chorvatštiny, slovinštiny, srbštiny, krymské tatarštiny, estonštiny, finštiny, livonštiny, vietnamštiny, ázerbájdžánštiny, turečtiny, uzbečtiny, grónštiny, inupiaku
- Z není obsaženo v abecedě: faerštiny, islandštiny, irštiny, velštiny, vietnamštiny, fidžijštiny, jorubštiny, ajmarštiny, guaraní, grónštiny, inupiaku, komančštiny
- Jak mohou být tato písmena považována za základní, když se nevyskytují v tak velkém množství jazyků? --Standazx 5. 6. 2010, 05:00 (UTC)
- Je to možno nazývat jako základní, ale pro ta odvozená písmena, nikoliv pro písmo. K otázce jsem se vyjádřil mnohokrát - písmeno lze považovat za základní, pokud se vyskytuje ve více než pár abecedách. Už mě tato diskuse opravdu silně unavuje, nebudu se jí dále účastnit, tedy alespoň dokud někdo nepřinese nový vítr. Nezlobte se. Palu 5. 6. 2010, 09:35 (UTC)
- Ano, vyjádřil, ale vždycky ve smyslu víc než pár nebo většina. Na mojí otázku, kolik by to mělo být, zarytě mlčíte. Měla by za základní písmena tedy být považována písmena vyskytující se ve více než dvou abecedách? Nebo ve více než v pěti abecedách? Nebo ve více než v 10 abecedách? Ve více než ve 100 abecedách? V alespoň 10 % abeced? Alespoň v 30 % abeced? Alespoň v 50 % abeced? Nic takového jste zatím ve vašich odpovědích neuvedl. --Standazx 5. 6. 2010, 18:11 (UTC)
- Je to možno nazývat jako základní, ale pro ta odvozená písmena, nikoliv pro písmo. K otázce jsem se vyjádřil mnohokrát - písmeno lze považovat za základní, pokud se vyskytuje ve více než pár abecedách. Už mě tato diskuse opravdu silně unavuje, nebudu se jí dále účastnit, tedy alespoň dokud někdo nepřinese nový vítr. Nezlobte se. Palu 5. 6. 2010, 09:35 (UTC)
- Takže děkuji za vysvětlení významu slova základní. Já se totiž domníval, že slovo základní je odvozeno od slova základ, tudíž pokud něco slouží jako základ (něco, na čem se dále dá stavět), může se k tomu bez problémů přidat přídavné jméno základní (např. v počítačové terminologii základní deska = deska, která je základem počítače). Takže přestože Þ je základem pro písmena Ꝥ, Ꝧ, Þ̀, Þ̈, Þ̢, není možné ho nazývat slovem základní. Na druhou stranu vás obdivuji, že máte jednoznačné argumenty k problematice, ke které se nechce vyjádřit ani ÚJČ z důvodu nedostatku podkladů (nechtěl byste jim to vysvětlit, aby v tom také měli jasno?). Odpověď z ÚNMZ zní (cituji): V normě se slovo základní používá pro písmena bez diakritiky. Každopádně jste mi ještě neodpověděl jednoznačně na otázku, v kolika abecedách se musí dané písmeno vyskytovat, aby podle vás bylo možné ho považovat za písmeno základní. Některé písmena prostě jazyky nepoužívají:
- Þ je výchozí pro ta písmena, ale základní = tvořící východisko něčeho, hlavní, nejdůležitější. To tohle písmeno z hlediska latinky jako písma nesplňuje, už jen proto, že jej používá jen jedna nebo dvě modifikace latinky. Vše už bylo tak nějak řečeno a už jsem psal, že mi ta debata přijde absurdní. Zdroje výše uvedené jasně základní latinku definují a my tu podle mě řešíme s prominutím naprostou kravinu. Myslím, že jsme se už vyčerpali a nové argumenty nepřijdou, a tak bych asi počkal, jestli nepřidá někdo další nějaký zajímavý názor nebo třeba shrnutí této diskuse. Taky ještě budu rád, když dodáte vyjádření ÚNMZ až ho budete znát, snad také přispěje k dořešení této záležitosti. Palu 30. 5. 2010, 18:58 (UTC)
- Přiznám se, že nerozumím. Které písmeno tedy slouží jako základ pro písmena Ꝥ, Ꝧ, Þ̀, Þ̈, Þ̢, když to podle vás není písmeno Þ ? A znovu opakuji, že ÚJČ nemyslel nic nijak, pouze ocitoval jeden odstavec normy a pro výklad pojmu základní písmena mě odkázal na ÚNMZ, jehož názor je tedy podle mě rozhodující, jelikož ÚNMZ je správcem oné normy. --Standazx 30. 5. 2010, 18:47 (UTC)
- No, právě že výchozí absolutně není, ani nemá ve výchozí abecedě původ. Myslím, že ÚJČ písmeno Þ určitě nemyslel. Palu 29. 5. 2010, 10:06 (UTC)
- Přesně tak, evidentní je, že se ÚJČ vyjádřil tak, že nemůže podat kvalifikovanou odpověď, když pouze ocitoval normu, a proto mě odkázal na ÚNMZ, aby mi o tom sdělili víc. A ÚNMZ se vyjádřil podle mě jednoznačně v tom, že pro písmena platí základní = bez diakritiky. Jinak i podle definice slova základní patří Þ mezi písmena základní, protože je to výchozí písmeno (tvořící východisko něčeho, základní písmeno) pro písmena Ꝥ (šestnáctkový kód v Unicode: A764) Ꝧ (šestnáctkový kód v Unicode: A766) (ꝥ (šestnáctkový kód v Unicode: A765) ꝧ (šestnáctkový kód v Unicode: A767)). Navíc i výraz písmeno bez diakritiky a pozměněných tahů z odpovědi ÚJČ je platný pro Þ. --Standazx 29. 5. 2010, 05:46 (UTC)
- Co tím chce ÚJČ říci je podle mě evidentní. Kdyby do toho počítal i písmena, která se používají v 1 jazyku světa a která nikdo nezná, výslovně by je vyčetl. Dále si nemyslím, že byste se měl tázat regulátora češtiny na základní latinku, spíše se podívejme na definici slova "základní" (tvořící východisko něčeho, hlavní, nejdůležitější), která koresponduje s výše uvedenými zdroji, které exotická písmenka do základní latinky neřadí. Palu 24. 5. 2010, 06:50 (UTC)
- Jména a příjmení nejsou zrovna nejlepším důkazem pro výskyt znaků v daném jazyce. V českých textech se také vyskytují jména jako Josef Müller, nebo Jan Flüs, a přesto z nich nikdo nevyvozuje, že ü je součástí češtiny. ÚJČ se vyjádřil pouze tak, že základní mezinárodní abeceda se skládá z písmen bez diakritiky a pozměněných tahů. Bližší specifikace, např. to, že by z množiny písmen bez diakritikou měla být vyřazena písmena Þ či Ə, v odpovědi nevidím. Odpověď od ÚNMZ je v podobném smyslu: V normě se slovo základní používá pro písmena bez diakritiky. --Standazx 23. 5. 2010, 05:43 (UTC)
- V je v polštině exotické písmeno, ale v polských textech existuje (např. jméno Violetta Kubasińska). To ale neznamená, že budeme Þ řadit mezi základní písmena latinky. Ostatně tak se vyjádřil i ÚJČ. Pro zařazení Þ do základních písmen není žádné opodstatnění. Palu 16. 5. 2010, 17:46 (UTC)
- Věta, že V je omezeně součástí polské abecedy, je docela zajímavý výraz, zvláště, když hned v následující polské větě je uvedeno, že se nepočítá do písmen polské abecedy (dvě poněkud rozporná tvrzení, nemyslíte?). Každopádně je zvláštní, že Þ protože se vyskytuje málo, považujete za exotické písmeno latinky, ale V i přesto, že se v polštině vyskytuje málo, ho vzhledem k polštině za exotické nepovažujete. Přitom V je v polštině ve stejné situaci jako Þ v celé latince. Jinak jako příklad si dovolím uvést srbštinu, která písmena Q, W a X nepoužívá vůbec, slova do srbštiny se přepisují foneticky (např. software -> softver), na stránce sr:Isak Njutn jsou i další příklady jak se do Srbštiny přepisují jména (např. Lagranž). V srbštině se ani tato písmena vyskytovat nemohou, neboť nemají ekvivalenty v cyrilici. Podle srbského zákona jsou latinka a cyrilice v Srbsku rovnocenné.
- Toto je pouze komentář odpovědi wikipedisty Palu, nikoliv návrh řešení: Pokud vezmeme jednotlivá písmena latinky a stanovíme jako kritérium toho, zda se písmeno používá v daném jazyce či nikoliv, to zda je obsaženo v abecedě daného jazyka, zjistíme, že různá písmena písmena jsou využívána v různém počtu jazyků. Některá nejsou používána v žádném jazyku, některá ve všech jazycích používajících latinku, jiná třeba v 90% jazyků, jiná v 70% jazyků, jiná v 10% jazyků. Jak navrhuje Okino, mohou být jako základní písmena zvolena písmena, která se vyskytují alespoň v jednom zdroji nebo naopak která se vyskytují pouze ve všech zdrojích. Vzhledem k tomu, že jsem zatím nenašel oficiální definici pojmu základní písmena latinky, můžeme prozatímně za zdroj o oficiálních písmenech považovat výskyt písmen v abecedách jednotlivých jazyků. Tedy za základní písmena můžeme považovat buď písmena vyskytující se alespoň v jedné abecedě a nebo pouze písmena, která se vyskytují ve všech abecedách. V prvním případě tedy písmena anglické abecedy + Þ, ß, Ə, v druhém případě pouze písmena A, B, D, E, F, G, H, I, L, M, N, O, P, R, S, T, U - písmena K, Q, W, Y nejsou součástí rumunské abecedy, písmeno V není součástí polské abecedy, písmena J a Z nejsou součástí vietnamské abecedy, písmeno X není součástí lotyšské a litevské abecedy, písmeno C není součástí islandské, faerské, uzbecké a estonské abecedy (estonská abeceda neobsahuje písmena C, Q, W, X a Y), turecká abeceda neobsahuje písmena Q, W, X, chorvatská, slovinská a srbská abeceda neobsahují písmena Q, W, X, Y. A to jsem zatím neprošel zdaleka všechny abecedy. --Standazx 9. 5. 2010, 18:46 (UTC)
- Výše uvedená diskuse je uchovávána jako archiv žádosti o komentář. Laskavě ji neměňte. Případné další debaty patří na příslušnou stránku (na diskusní stránku článku nebo uživatele). Na této stránce by už neměly být prováděny žádné editace.